
The claim made by OpenAI regarding their whisper module supporting over 90 languages for AI-based open-source speech-to-text is, unfortunately, NOT accurate. This article delves into the accuracy issues of the whisper module across these languages and presents the findings of a survey covering 98 languages utilizing the whisper module.

Some Technical Details of Whisper
Whisper comes in different sizes such as tiny (trained with 39 million parameters), base (trained with 74 million parameters), small (trained with 244 million parameters), medium (trained with 769 million parameters), and large (trained with 1.5 billion parameters). This survey study was conducted on the base size of the whisper module.
For those curious about setting up Whisper on their local environments, simply execute the following command (assuming Python is already installed on your system).
pip install openai-whisperNote that this survey was conducted on ToText 1.2 version running on Python 3.10.2 version. ToText has the openai-whisper (version 20230308) python module installed and uses Whisper’s “base” size. Here is a code sample of how to use the model:
model = whisper.load_model("base")result = model.transcribe(_audio_file_path, language=_lang)print(result["segments"])For more technical details, please check out this GitHub page.
Navigating Challenges of ToText’s Language Accuracy
In 2023, Fatih Sen, a computer science professor, developed ToText, an ai-based, online, and free transcription service. He used OpenAI’s open source whisper module for the transcription and included 99 languages in the ToText platform.
After the ToText platform was launched, he began receiving unfavorable and unpleasant feedback from users. Certain languages were functioning poorly, while others weren’t functioning at all. This got him thinking. It wasn’t ideal to inform users that his system supported up to 99 languages when many of them weren’t functioning properly. He reached a point where each language needed thorough testing.
As a solo entrepreneur juggling a full-time job, he knew that conducting such an experiment required more than one person’s effort; it needed teamwork. That’s when he had a lightbulb moment: why not propose this experiment to the capstone class students? This wasn’t his first time suggesting and supervising a capstone project at the department of computer science where he work at; he had done it before. He proposed the idea, and fortunately ToText was chosen by a team in the capstone class. It was time to guide those capstone students who took on this project and begin testing all those languages.
A capstone project is senior-level project course that allows students to solve a real-world problem towards the end of their major. The course instructors assign projects involving collaborations with organizations or companies seeking solutions to real problems. Instead of just reading textbooks or taking exams, students team up with real people or companies facing real challenges. This hands-on experience gives them priceless industry insights and prepares them for the real world before they graduate.
Let’s Get Started: Conducting a Comprehensive Survey Study
Using the ToText platform, the capstone team conducted a survey study with native speakers of 98 languages in person as well as through Zoom or FaceTime.
They interviewed 2 to 3 people for each language, with the scores being 0 – makes no sense at all to 5 – perfect transcription. They used various famous phrases/songs/bible verses that were in the native language and transcribed those and then asked the native speakers to score out of 5. They took the averages of the scores for the final score of each language. Note that the team could not find any native speakers for the 12 languages (Table 1) in its first round. Also, the Hindi language transcription does not work at all. Instead, the whisper module translates the speech in the video to English.
Survey Results
The capstone team obtained the following results after conducting survey for the 98 languages:
| LANGUAGE | ROUND 1 SCORE (Out of 5) | ROUND 2 SCORE (Out of 5) | AVERAGE |
| Polish | 5 | 5 | 5 |
| Russian | 5 | 5 | 5 |
| Galician | 4 | 4 | 4 |
| Lithuanian | 4 | 4 | 4 |
| Norwegian | 4 | 4 | 4 |
| Nynorsk | 4 | 4 | 4 |
| Portuguese | 4 | 4 | 4 |
| Romanian | 4 | 4 | 4 |
| Slovak | 4 | 4 | 4 |
| Spanish | 4 | 4 | 4 |
| Javanese | could not fine any native speaker | 4 | 4 |
| Sindhi | could not fine any native speaker | 4 | 4 |
| English | 3.5 | 4 | 3.75 |
| Swedish | 3.5 | 4 | 3.75 |
| Bulgarian | 3 | 4 | 3.5 |
| French | 3 | 4 | 3.5 |
| Hebrew | 3 | 4 | 3.5 |
| Italian | 3 | 4 | 3.5 |
| Azerbaijani | 3 | 3.5 | 3.25 |
| Indonesian | 3 | 3.5 | 3.25 |
| Japanese | 3 | 3.5 | 3.25 |
| Bengali | 3 | 3 | 3 |
| Korean | 3 | 3 | 3 |
| Macedonian | 3 | 3 | 3 |
| Malay | 3 | 3 | 3 |
| Serbian | 3 | 3 | 3 |
| Ukrainian | 3 | 3 | 3 |
| German | 2.5 | 3 | 2.75 |
| Arabic | 2 | 3.5 | 2.75 |
| Slovenian | 2 | 3 | 2.5 |
| Thai | 2 | 3 | 2.5 |
| Turkish | 2 | 3 | 2.5 |
| Vietnamese | 2 | 3 | 2.5 |
| Dutch | 2 | 3 | 2.5 |
| Welsh | 2 | 2.5 | 2.25 |
| Finnish | 2 | 2.5 | 2.25 |
| Hungarian | 2 | 2.5 | 2.25 |
| Greek | 2 | 2 | 2 |
| Kazakh | 2 | 2 | 2 |
| Lao | 2 | 2 | 2 |
| Latin | 2 | 2 | 2 |
| Maori | 2 | 2 | 2 |
| Persian | 2 | 2 | 2 |
| Shona | 2 | 2 | 2 |
| Telugu | 2 | 2 | 2 |
| Turkmen | 2 | 2 | 2 |
| Urdu | 2 | 2 | 2 |
| Bosnian | 2 | 2 | 2 |
| Icelandic | 2 | 2 | 2 |
| Bashkir | could not fine any native speaker | 2 | 2 |
| Tagalog | could not fine any native speaker | 2 | 2 |
| Belarusian | 2 | 1 | 1.5 |
| Chinese | 2 | 1 | 1.5 |
| Albanian | 1 | 2 | 1.5 |
| Armenian | 1 | 2 | 1.5 |
| Catalan | 1 | 2 | 1.5 |
| Croatian | 1 | 2 | 1.5 |
| Danish | 1 | 2 | 1.5 |
| Luxembourgish | 1 | 2 | 1.5 |
| Punjabi | 1 | 2 | 1.5 |
| Tamil | 1 | 2 | 1.5 |
| Amharic | 1 | 1 | 1 |
| Basque | 1 | 1 | 1 |
| Breton | 1 | 1 | 1 |
| Faroese | 1 | 1 | 1 |
| Gujarati | 1 | 1 | 1 |
| Haitian Creole | 1 | 1 | 1 |
| Hausa | 1 | 1 | 1 |
| Latvian | 1 | 1 | 1 |
| Lingala | 1 | 1 | 1 |
| Maltese | 1 | 1 | 1 |
| Mongolian | 1 | 1 | 1 |
| Myanmar | 1 | 1 | 1 |
| Pashto | 1 | 1 | 1 |
| Sanskrit | 1 | 1 | 1 |
| Sinhala | 1 | 1 | 1 |
| Somali | 1 | 1 | 1 |
| Sundanese | 1 | 1 | 1 |
| Tajik | 1 | 1 | 1 |
| Yiddish | 1 | 1 | 1 |
| Hawaiian | could not fine any native speaker | 1 | 1 |
| Kannada | could not fine any native speaker | 1 | 1 |
| Khmer | could not fine any native speaker | 1 | 1 |
| Tibetan | could not fine any native speaker | 1 | 1 |
| Czech | 0 | 1 | 0.5 |
| Nepali | 0 | 1 | 0.5 |
| Afrikaans | 0 | 0 | 0 |
| Assamese | 0 | 0 | 0 |
| Estonian | 0 | 0 | 0 |
| Georgian | 0 | 0 | 0 |
| Swahili | 0 | 0 | 0 |
| Uzbek | 0 | 0 | 0 |
| Yoruba | 0 | 0 | 0 |
| Malayalam | could not fine any native speaker | 0 | 0 |
| Marathi | could not fine any native speaker | 0 | 0 |
| Occitan | could not fine any native speaker | 0 | 0 |
| Tatar | could not fine any native speaker | 0 | 0 |
| Hindi | translates to english | translates to english | N/A |
Below, you can see a graph of survey results of 98 languages using the whisper module. The average scores from Table 1 were used for this graph.
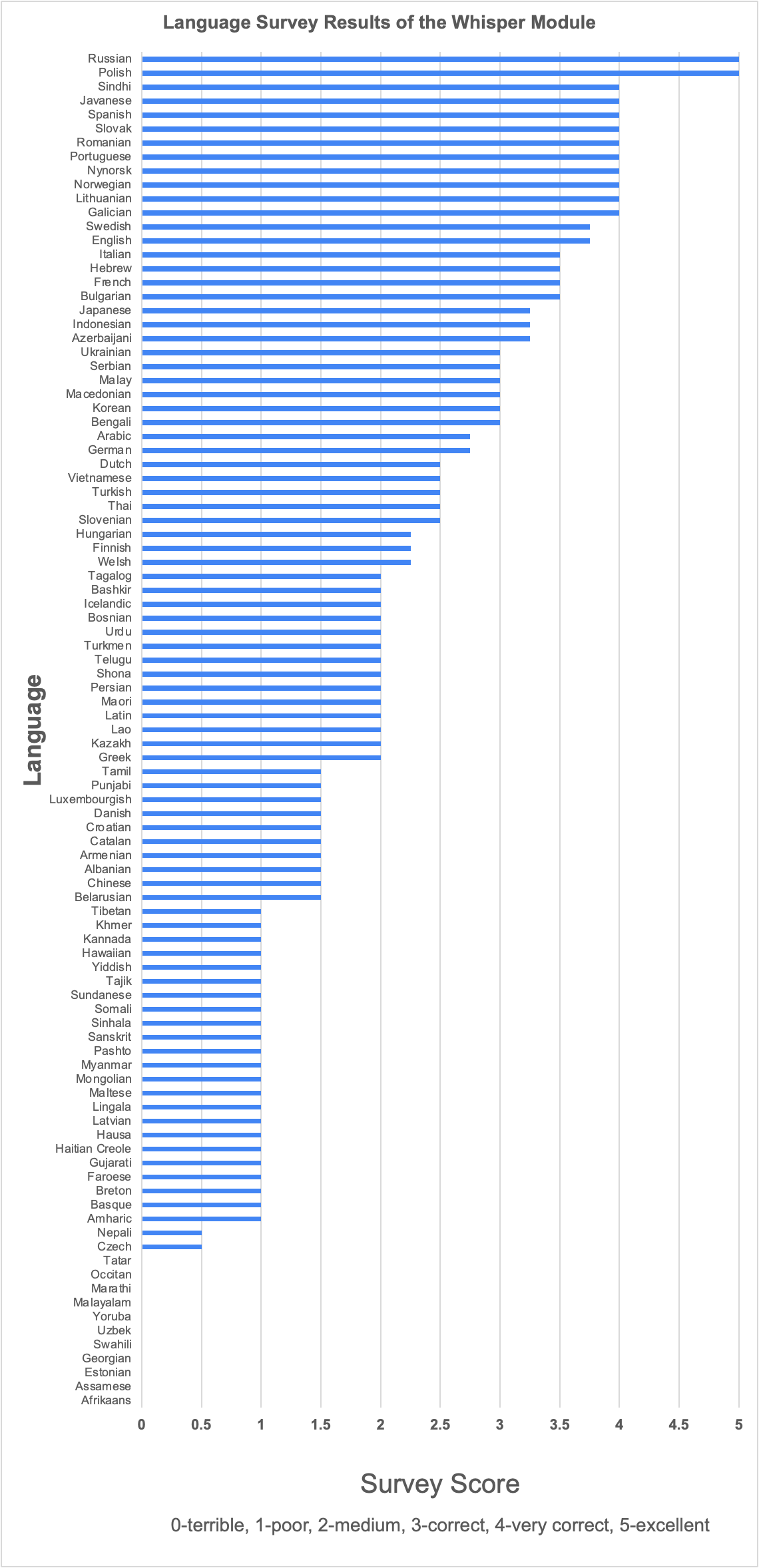
The team had two rounds. In the first round, they interviewed only a single native speaker for three different videos. In the second round, they interviewed multiple native speakers per language. Here is the summary of survey results.
- 2 languages had an average score of 5, which is excellent (perfect transcription).
- 10 languages had an average of 4 which is very good (very correct transcription).
- 15 languages received an average between 3 and 4 which is good (correct transcription).
- 24 languages obtained an average score between 2 and 3 which is average (medium transcription).
- 33 languages received an average score between 1-2 meaning the transcriptions were minimally correct (poor transcription).
- The rest of languages had an average score below 1, meaning the transcriptions made no sense at all (terrible transcription).
- 1 language (Hindi) would not transcribe but translate instead.
Language-Specific Insights
Polish and Russian: It was surprising to see these languages performing the best among other languages. The relatively high scores in these languages could indicate a stronger dataset presence or more effective training of the AI models specific to these linguistic patterns. Because there are a small number of speakers it may be possible that the language does not have many dialects, so is easier to get a holistic view of the language. For Russian, it’s likely that there is one main way of speaking that reaches the internet, so it does not take into account some more unorthodox dialects or accents. It’s worth exploring why these languages yield better results to potentially apply similar strategies to the underperforming languages.
English and Chinese: These languages are among the most widely spoken globally, meaning there’s a diverse range of accents and dialects likely present in the dataset. Chinese isn’t even really a language as Mandarin and Cantonese are both accepted “Chinese” languages. Because of the variety of the data in the dataset, it makes sense that these wouldn’t be perfect and the Chinese translation makes even more sense being bad, considering that it is such an inaccurate generalization.
Galician, Lithuanian, Nynorsk, Javanese, Sindhi: It’s remarkable how these less-known and uncommon languages scored highly. They even surpassed widely used languages like English, German, and French. However, it’s worth noting that native speakers for Javanese and Sindhi were not available in the initial round. Therefore, it’s prudent to approach these two languages with caution, as their scores might have been lower with native speaker input in the first round.
Czech, Nepali, Afrikaans, Assamese, Estonian, Uzbek,… Hindi: The exceptionally low scores (below than 1) for these languages suggest that Whisper’s transcription algorithms may lack the necessary nuances of these linguistic structures or that the audio quality in the test cases was insufficient for accurate transcription. It’s critical to investigate whether these languages suffer from systemic issues within the transcription service, such as poor recognition of accents or dialects. Hindi does not even work with the model at all. When the module tries to transcribe to Hindi it just translates it to English instead.
Refining ToText: Enhancing Transcription Accuracy
Following the survey results, 48 languages, including Malagasy which wasn’t tested by the capstone team, were removed from ToText. As of May 2024, only 51 languages scoring 2 or higher were retained for user access. Additionally, the claim “…with over 95% accuracy.” was removed from the main page. This change was made due to the difficulty in defining a specific accuracy metric given the platform’s support for multiple languages.
ToText has the potential to enhance its accuracy by shifting from the “base” size to the “large” size. It’s worth noting that the initial experiment utilized the base size, and further investigation through a separate survey study would be necessary to gauge any significant accuracy improvements with larger sizes across different languages. However, employing a larger size like “large” would necessitate a minimum of 10GB memory and could potentially impact performance. At this stage, it’s advisable for ToText to continue with the base model to avoid additional costs associated with hardware upgrades, increased memory usage, and potential performance issues. Nonetheless, this transition could mark a positive stride for ToText as it endeavors to provide enhanced transcription services with thoroughly trained datasets and parameters.
A different approach to improving transcription accuracy is to explore speech-to-text AI services offered by companies other than OpenAI. Companies like Amazon, Google, IBM, and others provide such services, which could be worth considering for future use by ToText.
At present, ToText is freely accessible to all users. If the ToText team intends to monetize the platform, one strategy to explore is integrating human involvement. While AI technology continues to advance, human input remains crucial for accurate transcription. Therefore, as part of future developments, the ToText team could explore incorporating human assistance alongside AI capabilities. This approach can enhance transcription accuracy and potentially generate substantial revenue for the platform.
Conclusions
The variance in scores across different languages points to a significant inconsistency in Whisper’s performance. This inconsistency could stem from varied dataset sizes, the complexity of phonetic and grammatical structures, or differing levels of commercial and research focus within the AI development community for these languages.
Whisper (base size) is a good tool for homogeneous languages, especially for romance languages known as the Latin or Neo-Latin languages. Many times for languages that are not based in Latin or don’t have a similar alphabet to it, the model will just return a phonetic transcription which is much less useful. It is possible that some tweaking needs to be done so the model can have a better definition of what a transcription actually is. Whisper is fine for personal use for most people who reside in a Western country but for larger-scale projects, it would need a lot of work, as it is not perfect even for the romance languages.
These results could be beneficial for OpenAI for improving their whisper module to have a better transcription service, especially for those low-performing languages.

From left to right: Dr. Amy Cook (capstone course instructor), Elijah Lewis (capstone course student), Kamaal Orgard (capstone course student), Jaylon Taylor (capstone course student), Dr. Fatih Sen (owner of ToText, comp sci instructor and capstone project supervisor), Dr. Brandon Booth (capstone course instructor).

Leave a comment